안녕하세요?
지난번 포스팅에서 어떻게 복잡한 공식을 불러와서 작업을 해야만 하는 작업을 간단하게 끝낼 수 있었습니다. 이제는 나머지 조건에서도 이런 유의차가 나오는지 아닌지 알아봐야 하는 시간이 왔으니, 한번 통계처리에 들어가 보도록 합니다.

이제는 평균과 표준편차를 이용해서 계산을 하는 조건에 들어가서, 여기서는 일단 위 스크린샷에서 보이는 것처럼 어떻게 해서 변동과 고정 account risk별로 가장 수익이 좋았는 10개만 가지고 와서 일단 정렬을 하도록 합니다.

그리고 나서 F 검정을 이용하기 위한 준비를 하도록 합니다. 당연하다면 당역하게도 윗쪽에 있는 변수 1은 고정 Account Risk를 쓰도록 하고, 변수2가 변동 Account Risk를 사용합니다.

먼저 위 스크린샷에서 볼 수 있는 것과 같이 일단 P값이 제대로 나오는 것을 확인할 수 있기는 있었습니다. 여기서 제가 판단을 잘못 했습니다.

여기서 잘못 판단을 했기 때문에 제가 등분산 가정 두 집단이라는 통계적 처리를 해 버리고 말았습니다. 일단 이렇게 한 다음에.........

그리고 나서 다음으로 역시 언제나 처럼 변수1과 변수2를 일단 입력하고 나서 시작해 보도록 합니다. 이렇게 하고 나서 다음의 작업을 해 보도록 합니다.
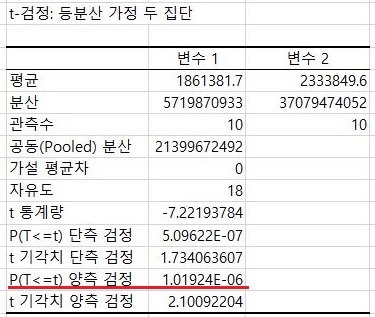
이렇게 해서 일단 위 스크린샷에서 보이는 것처럼 0.05 미만이라서 유의차가 있는 상황에서 일단 더 수익이 증가했다는 것을 알 수는 있었습니다. 그런데 근본적으로 이게 잘못 되었기 때문에, 어떻게 해서든 다시 테스트를 해야 합니다.
등분산이 성립되지 않기 때문에, 위 스크린샷에서 볼 수 있는 것처럼 이분산 가정 두집단으로 해야 했었는데, 그걸 하지 않아서 생기는 문제 였습니다.

이렇게 해서 통계적인 처리를 해도, 여전히 위 스크린샷에서 볼 수 있는 것처럼 유의수준 이하이기 때문에 일단 유의차가 있는 것으로 나옵니다. 이제 이걸 바탕으로 해서 봐도, 변동 Account Risk를 사용하는 경우가 평균과 표준편차를 이용한 매도/매수 조건에서 수익이 더 증가한 것을 확인할 수 있었습니다.
'무모한 도전-주식 인공지능 만들기' 카테고리의 다른 글
| 1차 테스트의 데이터 분석 -5-complete (0) | 2020.06.06 |
|---|---|
| 1차 테스트의 데이터 분석 -4- (0) | 2020.06.05 |
| 1차 테스트의 데이터 분석 -2- (0) | 2020.06.05 |
| 1차 테스트의 데이터 분석 -1- (0) | 2020.06.05 |
| Account Size를 결정하기 위한 1차 테스트 (0) | 2020.06.04 |



