안녕하세요?
지난번 시간에 또 다른 문제가 기다리고 있었다고 했는데, 실제로 단 한번의 시도로 간단한 아이디어는 제대로 구현이 되지 않았고, 거의 두자리수에 가까운 시도가 있고 나서야 어느정도 만족할 만한 알고리즘이 나오는 데 성공했다고 할 수 있습니다. 아무튼 중간에 다른 일이 있어서 하루종일 못하기는 했지만, 그대로 거의 아이디어 하나 구현하는데 일주일이 걸렸다는 것을 알 수 있었습니다.

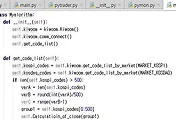
일단 위 스크린샷은 제가 아이디어를 구현하는데 사용이 된 가장 핵심이 되는 메서드입니다. 이 매서드에서 먼저 키움증권 openAPI로 부터 종목코드를 받아온 다음에, 이 코드들을 가지고서 첫번째 for loop를 돌렸고, 그 다음에 한 종목의 현재가가 얼마나 많은가로 부터 두번째 for문을 돌렸습니다.

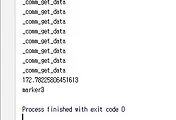
그런데 이렇게만 해서는 위 스크린샷처럼 에러가 뜨면서 제대로 완료가 되지 않는 문제점이 나오는 것을 확인할 수 있었습니다.

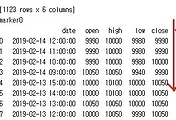
거기다가 일단 나중에 엑셀로 열어서 정리하기에도 그다지 적합하지 않은 형태로 텍스트 파일에 기록이 되는 것을 확인할 수도 있었습니다.

일단 가지가지로 무언가 문제가 많지만 가장 해결하기 쉬운 것부터 해결을 하고자 위 스크린샷처럼 먼저 dataframe형태의 자료를 그대로 출력하면 dtype과 같은 필요없는 정보까지 나오기 때문에, float형태로 바꾸고, 그 다음에 str형태로 바꾸도록 했습니다.

다음으로는 위 스크린샷과 같이 500개의 종목코드는 너무 길어서 문제를 일으킨 것 같다는 생각이 들어서, 한번 300개로 줄여서 시도를 해 보았습니다.

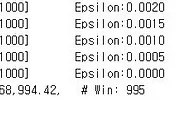
어러는 와중에 2번째 강화학습이 완료가 되어서 모델이 저장된 것을 확인할 수 있었습니다. 일단 여기까지 보면 강화학습 자체는 순조롭게 진행이 되고 있다고 할 수 있습니다.

그 다음으로 어디서 계산을 지연하는 문제가 있는가 했더니, 위 스크린샷처럼 빈 배열을 선언하는 문장이 for문 밖에 있는데, 이러면 종목코드가 새로 들어오든 말든 이전에 있던 데이터가 초기화 되지 않는 문제점이 있습니다. 그래서 for문 안으로 들어와서 새로운 종목코드가 들어오면 새로운 초기화가 되도록 만들어 줍니다.

그렇게 해서 제대로 프로그램이 완료가 되는 것을 확인할 수 있었습니다. 이렇게 하는 것으로 이제 찝찝하지 않고 제대로 된 데이터를 얻는 것이 가능하다는 생각이 들었습니다.

그리고 위 스크린샷처럼 제대로 된 종목의 코드와 절대 변화량의 평균까지 구하는 것이 가능해 졌습니다. 이렇게 하는 것으로 이제 다음 작업을 마음놓고 할 수 있게 되었습니다.

다음 작업은 위 스크린샷처럼 먼저 텍스트 파일의 이름을 바꾸어 주도록 합니다.

이후 하나하나 300 단위로 끊어서 작업을 이어가도록 해 봅니다.

두번째 작업도 시원하게 마무리가 되는 것을 확인할 수 있었습니다.

그리고 생각보다 많은 양의 종목이 절대 변화량 300을 초과한다는 것을 확인할 수 있었습니다.

계속해서 300단위로 끊어서 작업을 하도록 해 봅니다.

다음으로는 결과를 저장할 텍스트 파일의 이름도 바꾸어 주도록 합니다. 그런데 포스팅의 내용이 너무 길어지는 관계로 이번 포스팅은 여기서 한번 끊어 주도록 하겠습니다. 나머지 작업에 대해서는 다음 포스팅에서 이어서 나가며, 남은 작업의 결과도 올리도록 하겠습니다.
'무모한 도전-주식 인공지능 만들기' 카테고리의 다른 글
| 결과의 정리와 하나의 장벽 (0) | 2019.02.17 |
|---|---|
| 새로운 수익모델을 만들기 위한 종목찾기 알고리즘의 제작-5- (0) | 2019.02.16 |
| 새로운 수익모델을 만들기 위한 종목찾기 알고리즘의 제작-3- (0) | 2019.02.15 |
| 새로운 수익모델을 만들기 위한 종목찾기 알고리즘의 제작-2- (0) | 2019.02.15 |
| 새로운 수익모델을 만들기 위한 종목찾기 알고리즘의 제작 (0) | 2019.02.14 |