안녕하세요?
지난번 포스팅에서는 어떻게 해서 과다한 시세조회 요구가 나오도록 어떻게 돌리는 데 까지는 성공했습니다만, 문제는 아직도 많이 남아 있기는 있습니다. 우선 어떻게 어디서 부터 어디까지 자를 것인가를 두고서 한번 작업을 하기는 해 보아야 한다는 것 입니다.

먼저 제가 만들어 보고자 아는 알고리즘을 만들기 위해서 위 스크린샷처럼 한번 작업을 하도록 해 봅니다. 먼저 kospi에서 얻어온 종목코드들이 500개를 넘는다면, 위 스크린샷처럼 한번 0에서 500까지 잘라서 작업을 하도록 만들어 보도록 합니다.

그리고 그 결과를 txt파일에 저장을 하도록 했는데 위 결과처럼 절대값으로 변환한 변화량의 평균이 나오는 것을 확인할 수 있었습니다.

여기서 만족할 수는 없고, 다음으로 501번째 부터 1000번째 코드를 다음으로 가지고 와서, 평균 변화량의 크기가 300 이상이 나오는 지에 대해서 검사를 하도록 합니다.

그리고 나서 위 스크린샷처럼 treasureBox2.txt라는 식으로 새 텍스트 파일에서 한번 저장을 하라는 식으로 명령을 내려서 작업을 진행하도록 만들어 보았습니다.

위 스크린샷처럼 한번 작업을 마쳐서 두번째 작업이 끝나기는 했습니다만, 여기서는 어떻게 된 것인지 300이상의 변화량을 보이는 기업이 나오지 않았습니다.

이제 1001번째에서 1500번째까지 한번 찾도록 만들어 봅니다.

그리고 나서, 위스크린샷처럼 새로운 텍스트 파일에서 작업을 하도록 만들어 보도록 합니다.

결국 그렇게 많지 않은 종목들이 나오는 것을 볼 수 있었습니다. 그런데 여기서 절대값 평균을 한번 찾아보니, 위 스크린샷처럼 000120이라는 종목의 변화량이 가장 많은 것으로 나오는 것을 볼 수 있었습니다.

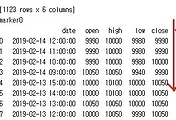
그런데 상당한 문제가 나오는 것을 볼 수 있었습니다. 일단 종목코드 000120이라는 종목이 바로 동화제약인데, 이 회사의 60분봉 차트를 직접 가지고 와서, 여기서는 변화량이 1082라는 값으로 나오는 것을 볼 수 있었습니다.

그래서 일단 데이터 베이스 파일에 저장된 데이터 중에서 일부만을 추출해서 한번 강화학습에 들어가 보도록 합니다. 물론 2018년 10월 1일부터 만들어 졌다면, 너무 학습할 데이터의 양이 많기 때문에, 하는 수 없이 위 스크린샷처럼 328개의 데이터만 만들어 보도록 했습니다.

그리고 나서 이번에는 yellowoperation이라는 프로젝트를 열어서 위 스크린샷처럼 데이터 베이스 명을 이제 바꾸어 주도록 합니다.

그리고 나서 구글 드라이브에 위 스크린샷처럼 업로드를 시켜 주도록 합니다. 그리고 당연하다면 당연하게도 main.py가 기존에 있는데, 이걸 제거하고 올려야 합니다.

그런데 처음에 했더니 왜인지 계속해서 관망만을 하는데, 그 이유를 알았습니다. 동화제약은 AJ렌터카와는 다르게 1주당 10만원을 넘기 때문에 초기 자본금 10만원으로는 도저히 어떻게 할 수 없었습니다. 그래서 초기 자본금을 100만원으로 올려 줍니다.

그런데 이렇게 강화학습을 다 마치고 나서 저장이 되지 않는 사태가 벌어지는 것을 볼 수 있었습니다. 일단 이 문제는 이 문제대로 해결을 해 나가도록 하고, 지금 당면한 당장 큰 문제라면 당연하게도 왜 python 상에서 계산한 변화량의 평균하고 직접 60분봉 차트에서 추출한 변화량의 평균이 다른가 하는 것 입니다.
'무모한 도전-주식 인공지능 만들기' 카테고리의 다른 글
| 새로운 수익모델을 만들기 위한 종목찾기 알고리즘의 제작-4- (0) | 2019.02.15 |
|---|---|
| 새로운 수익모델을 만들기 위한 종목찾기 알고리즘의 제작-3- (0) | 2019.02.15 |
| 새로운 수익모델을 만들기 위한 종목찾기 알고리즘의 제작 (0) | 2019.02.14 |
| 60분봉차트를 이용한 도전 part2 (0) | 2019.02.11 |
| 60분봉 차트를 이용한 도전 part1 (0) | 2019.02.10 |