안녕하세요?
이번 포스팅에서는 지난번 시간에 AJ렌터카의 주식을 기준으로 인공지능 주식투자를 시작했는데, 일단 학습 데이터를 바탕으로 여러번 기계학습을 시키고, 그 결과는 가 나왔습니다. 그래서 이번 포스팅에서는 이전의 주식 데이터-2016년 5월 19일 부터 2018년 4월 23일까지 데이터를 바탕으로 어떻게 하면 포트폴리오 가치(PV)를 증가시키라고 명령을 했습니다. 그래서 이번에는 그 결과를 보여 드리고자 합니다.

먼저 첫번째 [파이썬과 케라스를 이용한 딥러닝/강화학습 주식투자]의 조건 그대로 기계학습을 했는 결과 입니다. 여기서 10번 기계학습을 했는 에포크 10의 결과에서는 3번째 PG라고 적혀있는 그래프를 보시면 노란색 막대가 많은 것을 보실 수 있는데, 이게 무작위 행동을 했다는 것으로 10번의 기계학습을 했는 결과에서는 엄청나게 많은 랜덤한 행동을 했다는 것을 확인할 수 있습니다.
그리고 200번째 기계학습의 결과에서는 그렇게 까지 나아지는 것을 볼 수 없었으며, 여전히 무작위 투자를 많이 하는 것을 볼 수 있었습니다. 다만 포트폴리오 가치(PV)의 변화 역시...... 그렇게 많은 차이가 없다는 것을 볼 수 없었습니다.

600번째 기계학습에 들어가자 좀 무작위 행동이 많이 줄어들었으며, 1000번째 기계학습에서는 전혀 무작위 행동이 없는 것을 볼 수 있습니다. 이런 것으로 봐서 점점 학습이 진행이 되면 될수록 무작위 행동이 줄어 드는 것을 볼수는 있지만, 포트폴리오 가치는 전혀 변하지 않는 것을 볼 수 있습니다.

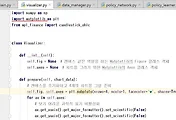
일단 에포트의 로그를 소실했기 때문에, 이 역시 판단에 중요하기 때문에, 이번에는 위 스크린샷의 붉은색 박스처럼 os.makedirs()라는 메소드를 사용해서 만약에 지정한 위치에 폴더가 없다면 폴더를 생성하라는 명령을 내려 주도록 합니다.

다음으로는 최대 거래 단위를 2에서 5로 늘려 주도록 하고, 지연보상 임계시점이라고 얼마나 이익이나 손실이 발생하였으면 학습을 진행할 것이냐고 할때, 0.02=2%의 이익이나 손실이 났을 때 학습이 일어나라고 지정을 해 주었습니다.

일단 이때는 몰랐지만, 조건이 바뀌면서 기계학습에 걸리는 시간이 좀 더 길어졌는데, 모르고 그 시간을 측정하지 않았습니다. 다만 확실한 것은 거의 2시간은 넘게 걸렸습니다.

이번에는 기계학습에서 종전에 20%에서 2%로 늘렸기 때문인지, 4번째 PV윈도우를 보시면 더 많은 거래가 일어난 것을 볼 수 있었지만, 전체적인 포트폴리오 가치가 변하지 않는 것을 볼 수 있습니다.

에포크 600 = 600번 기계학습을 한 경우에 앞서와 마찬가지로 무작위 행동이 없어지는 것을 볼 수 있으며, 1000번째 기계학습을 했는 경우에는 전혀 무작위 행동이 없는 것을 볼 수 있습니다. 하지만 이 경우에도 중간에 주가가 급 폭락하는 구간이 있는데, 이 구간에 제대로 대처를 하지 못한 것을 볼 수 있습니다.

그래서 조건이 다른 상태에서 에포크의 숫자를 다르게 설정을 해 보았습니다만, 이 역시 거래 횟수만 늘어났을 뿐, 포트폴리오 가치가 달라지는 것을 볼 수는 없습니다.

일단 조건2로 기계학습을 했는 것을 각각 10회, 200회, 600회, 1000회에 걸쳐서 표시한 것 입니다. 희얀하게도 전혀 매도를 결정한 것은 없고, 학습이 진행되면 진행이 될 수록 최대한 적게 사면서 더 높은 포트폴리오 가치를 올리도록 되었습니다. 한마디로 AJ렌터카의 주식은 그냥 사놓고 나서 기다리기만 하면 된다는 소리가 됩니다. 이래서야 이 인공지능 주식투자를 하는 이유가 있을까 하는 생각이 듭니다. 그것도 나쁘지는 않은 전략이기는 전략인게, 초기 자본금 10만원을 투입해서 16만원 가까이 만드는 것을 보면...... 거의 60%의 수익은 내는 듯 합니다.

이제 조건을 다시 바꾸어 보도록 합니다. 먼저 최대 거래 단위를 10으로 올리고, 다음으로 지연보상 임계수치를 0.01로 해서 1%의 수익이나 손실도 반영하도록 합니다. 그리고 마지막으로 discount_factor를 0.1로 주어서 먼 과거의 결정일 수록 가치를 깍아 내리도록 합니다.

정책 학습기(policy_learner.py)에 있는 discount_factor역시 0.1로 바꾸는 것을 잊지 말도록 합니다.

이제 기계학습에 들어갑니다. 그런데 여기서 부터 제대로 삐걱거리기 시작했는 것이 조건이 너무 상세했기 때문인가요? 이 때문에 전체적으로 계산을 하는데 4시간이나 걸리는 것을 확인할 수 있었습니다. 이래서야 효율이 매우 낮아졌다는 것을 확인할 수 있었습니다.

일단 4시간 이나 걸려서 만든 모델의 결과입니다. 이 조건에서도 조건2와 큰 차이가 없는 것을 확인할 수 있었습니다.

이번에도 학습이 진행되면 진행이 될 수록 무작위 행동이 줄어드는 것을 볼 수는 있는데, 여전히 PV값은 전혀 변함이 없는 것을 볼 수 있습니다.

그리고 나서 조건 2나 조건 3이나 변함이 없다는 것을 알 수 있었습니다. 이래서야 조건을 바꾼것이 큰 차이를 만든 것이 맞는지 의문이 듭니다. 특히 중간에 있는 주가가 큰 폭으로 떨어지는 것에 제대로 대처를 못하는 것도 똑같습니다.

마지막으로 조건3에서 기계학습을 10번, 200번, 600번, 1000번 했는 결과입니다. 이 결과에서도 매도는 한번도 없고 그냥 주식을 보유해서 가지고만 있는데 조건2에 비해서 떨어지긴 했지만 50%넘는 수익을 거두는 것을 볼 수 있습니다. 이래서야 이게 제대로 된 것이 맞는지 의문이 들기는 합니다만, 먼저 해결해야 할 것이 바로 계산에 걸리는 시간인데, 일단 GPU를 사용해서 계산속도를 더 빠르게 할 수는 없는지 알아보도록 하고, 이 현상에 대해서는 좀 나중에 해결책을 강구해 보겠습니다.
'무모한 도전-주식 인공지능 만들기' 카테고리의 다른 글
| GPU를 이용한 주식 인공지능의 학습 part2 (0) | 2018.11.03 |
|---|---|
| GPU를 이용한 주식 인공지능의 학습 part1 (0) | 2018.11.03 |
| 본격적인 RLTrader의 작동-모델 만들기의 시작 part4 (2) | 2018.11.01 |
| 본격적인 RLTrader의 작동-모델 만들기의 시작 part3 (7) | 2018.11.01 |
| 본격적인 RLTrader의 작동-모델 만들기 시작 part2 (4) | 2018.10.31 |