안녕하세요?
이번 포스팅에서 드디어 RLTrader의 마지막 모듈까지 모두 코딩을 하고서, 그 내용을 포스팅 하고자 합니다. 하지만 이러고도 주식 데이터를 가지고 오는 과정이 남아 있고, 또 이걸 HTS와 연계시키는 것 까지도 상당히 중요한 내용이라면 중요한 내용이 아직 남아 있습니다. 아무튼 그 첫 과정인 RLtrader를 구성하는 4가지 모듈을 다 코딩하는 내용을 보여드리겠습니다.

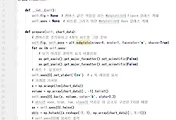
먼저 위 스크린샷은 지연보상이 발생한 경우에 학습을 수행하는 flt()함수의 부분입니다. 여기서는 148번째 줄에서 학습없이 메모리의 최대 크기만큼이나 batch_size가 찼을 경우에 지연보상을 한다고 하는데, 이 부분은 제가 기계학습에 대해서 아직도 잘 모르는 부분이 많아서 잘은 모르겠습니다.
그리고 158번과 160번줄에서 긍정 학습과 부정학습의 횟수를 계산합니다. 마지막으로 162번 줄에서는 train_on_batch()라는 함수를 이용해서 학습을 실행합니다.

다음으로는 하나의 에포크가 완료되어 에포크 관련 정보를 가시화 하는 코드인데, 167번째 줄에서 총 에포크의 문자열 길이를 재는데, 만약 에포크의 수가 1000이라면 문자열의 자리수가 4가 됩니다. 이어서 168번째 줄에서는 rjust()함수가 있는데 문자열을 자릿수에 맞도록 오른쪽으로 정렬해 주는 함수 입니다.

위 스크린샷의 코드는 에포크가 완료되면, 에포크에 관련 정보를 시각화(가시화)하는 부분이라고 볼 수 있습니다.

그리고 이어서 하나의 에포크 수행이 완료 되었기 때문에 전체 학습에 대한 통계 정보를 갱신하는 부분이며, 여기 198번째 줄에서 75번째 줄에서 완료한 for문이 끝나는 곳인데, 학습이 끝나지 않았다면 198번째 줄 다음에 75번 줄로 돌아가는 것을 의미합니다. 개인적으로는 C#과 다르게 파이썬에서는 {}기호가 없기에, 헷갈리지 않도록 조심, 또 조심하는 것이 중요하다는 생각이 듭니다.

그리고 이어서 fit()함수의 마지막 부분을 위 스크린샷이 보여주는데, for문을 벗어나=모든 에포크를 수행하고 나면, 최종 로그를 기록하는 부분이라고 할 수 있습니다.

다음에는 PolicyLearner에서 배치 데이터를 생성하는 _get_batch()함수를 보여줍니다. 이 배치 데이터의 크기는 지연 보상이 발생될 때 마다 결정되기 때문에, 매번 크기가 다릅니다.

다음은 학습 데이터를 다시 구성하는 샘플 하나를 생성하는 함수인 _build_sample() 를 보여 주는데, 여기서는 환경(environment) 객체의 observe()함수를 불러와서, 다음 학습의 인덱스가 있는지 없는지를 살펴보며, 다음 학습 인덱스가 존재하면 training_data_idx 변수를 1 증가시킵니다.

다음은 실제로 신경망 학습을 통해서 만든 모델을 바탕으로 투자를 하는 trade()라는 함수입니다. 여기서 신경망을 load_model을 적용시켜서 이전에 만들었는 모델을 불러오는 것을 볼 수 있습니다. 그리고 여기서는 학습이 아니라, 이미 만들어져 있는 모델로 투자를 하는 것이기 때문에, num_epoches는 1, learning은 False로 지정을 합니다.

그런데 위 스크린샷처럼 여전히 코딩을 다 마치고서도 여전히 저 에러들은 뜨는 것을 볼 수 있습니다. 이 에러들을 어떻게 해야 할지 아직은 모르겠는데, 아직 이게 RLtrader의 완성이라고 할 수도 없고, 아마 마지막으로 완전히 만들고 나면 이 에러들은 일단은 놔두도록 했습니다.

이로서 위 스크린샷처럼 4개.... 아니 5개나 되는 RLtrader의 중요 모듈을 만들어 내는데 성공했습니다. 그런데 이것만 가지고서 바로 주식투자 시뮬레이션을 할 수 있는 것은 아니고, 아직 남아 있는 과정이 많다는 생각이 듭니다. 그리고 이어서 주식 데이터를 가지고 오는데 역할을 할 모듈도 만들어야 하고, 아직까지는 PyCharm의 코드로만 존재하는데, 이걸 어떻게 프로그램으로 만들어서 써 먹을 지도 생각해야 하고............ 어찌 보면 정말 무모한 도전이기는 하지만, 그래도 계속해서 도전해 보고자 합니다.
'무모한 도전-주식 인공지능 만들기' 카테고리의 다른 글
| RLTrader에서 주식 데이터 전처리 모듈 만들기 (0) | 2018.10.29 |
|---|---|
| 키움증권 HTS(홈 트레이딩 시스템)인 영웅문4의 설치와 데이터 가지고 오기 (2) | 2018.10.29 |
| RLtrader의 제작 part5 (2) | 2018.10.21 |
| RLtrader의 제작 part4 (0) | 2018.10.20 |
| RLtrader의 제작 part3 (0) | 2018.10.19 |