안녕하세요?
이번 포스팅에서는 RLtrader의 마지막 남은 모듈인 정책 학습기 모듈을 만드는 과정을 포스팅 하고자 합니다. 그 전에 먼저 정책 학습기라는 것이 무엇이냐 하면, 에이전트, 환경, 정책신경망을 가지고 강화학습을 수행하는 모듈로, RLtrader의 몸통이라고 할 수 있습니다.

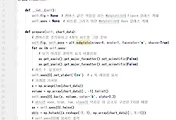
먼저 policy_learner.py의 첫 머리에서 위 스크린샷처럼 import를 여러개 만들어 주도록 합니다. 여기서 from이라는 말은 무슨 의미냐 하면, import하고자 하는 모듈이면 상위 패키지, 가져올 것이 클래스라면 상위의 모듈을 지정하는 명령어 입니다. 그리고 as는 import한 모듈, 패키지, 클래스, 함수를 다른 이름으로 사용하기 위한 키워드 입니다.

이어서 위 스크린샷이 클래스의 시작 부분입니다. 이 부분에서는 stock_code와 chart_data는 주식의 정보에 관련이 된 것이고, training_data는 학습과정에서 필요한 부분이라고 할 수 있습니다. 이어서 24번 줄에서 Environment클래스 객체를 생성시 chart_data를 넣어줍니다.
그리고 35~36번줄의 내용은 학습 데이터를 학습하기 위해 policyNetwork클래스의 객체를 생성하는 명령어라고 할 수 있습니다. 그리고 거의 마지막인 37번째 줄에서는 학습과정을 시각화 하기 위해서 Visualizer클래스의 객체를 생성합니다.

다음은 에포크마다 호출이 되는 reset()함수인데, 학습데이터를 처음부터 다시 읽기 위해서 self.training_data_idx를 -1로 재설정 하는 것을 볼 수 있습니다.

이어서 PolicyLearner의 핵심 메소드인 fit()함수를 설정하는 장면입니다. 문제는 이게 핵심이 되는 함수인 만큼, 상당히 메소드 자체가 길다는 것에 주의해야 합니다. 여기서 인자 선언부분에서 self를 제외하고서는 num_epoches는 몇번이나 반복 학습을 할 것인지를 정해주는 수치라고 할 수 있습니다.
그리고 max_memory라는 함수는 학습 데이터를 만들기 위해 과거 데이터를 저장할 배열이라고 할 수 있으며, discount_factor라는 인자는 할인요인이라고 해서, 더 과거에 결정한 행동의 보상에 더 가치를 깎는 수치라고 할 수 있으며, 0~1사이의 값을 지닐 수 있습니다. 그런데 여기서는 0으로 지정을 한 것으로 보아서, 할인 요인을 그렇게 주지 않는 듯 합니다.
start_epsilon:은 초기 탐헌 비율로, 무작위 투자를 통해서 경험을 쌓는 과정을 얼마나 되는 확률로 할 것인지를 결정하는 수치이며, 옆에 있는 learning은 이 값이 true이면 정책 신경망 모델을 만들지만, 이미 만들어진 정책 신경말 모델을 사용해서 투자를 하기 위해서는 이 값을 false로 두어야 합니다.

그리고 58번째 줄에서는 prepare()라는 함수를 이용하는 것을 볼 수 있는데, 주식의 일봉 차트는 거의 변하지 않으므로, 딱 한번만 시각화를 해주면 되기에 prepare()함수를 이용합니다.
그리고 이어서는 파이썬에서는 문자열에 숫자를 넣기 위해서는 %를 사용할 수 있으며, 파일 경로를 지정하기 위해서는 os.path.join(path)라는 함수를 사용할 수 있습니다. 다만 이 경우에는 path가 윈도우일 경우와 리눅스인 경우에 맞춰서 자동으로 구별해 준다는 점에서 매우 편리하다고 할 수 있습니다.
이후 os.path.isfile(path)라는 함수는 특이하게도 폴더가 아니라 path경로에 해당하는 파일이 있는지를 볼 수 있습니다. 그리고 os.mkdirs(path)라는 함수는 폴더가 없어도 path가 만들어 질 수 있도록 폴더를 아예 생성해 줍니다.

그리고 여기서 부터 상당히 중요한 것을 볼 수 있는게, for문이 75번 줄부터 시작이 되는데, 여기서 이 for문의 반복이 에포크의 수 만큼 반복을 해서, 이어서 198번째 줄까지 이어지는 것을 볼 수 있습니다. 그래서 각 에포크마다 이전의 상황을 초기화 하는 것을 볼 수 있습니다.

그리고 이어서 환경, 에이전트, 정책 신경망을 초기화 하고, 가시화 모듈까지 초기화 하는 것을 볼 수 있습니다. 그리고 여기서 중요한 것으로 학습을 진행할 수록 탐험비율을 감소 시키는 것을 볼 수 있습니다. 즉 epsilon의 값을 에포크가 진행이 되면 될 수록 감소가 되어서 100% 학습이 되면 전혀 탐험을 하지 않는 다는 것을 볼 수 있습니다.

다음으로는 하나의 에포크를 수행하는 wile문을 타이핑 했습니다. 여기서 샘플생성이라는 부분이 있는데, 이 부분은 행동을 결정하기 위한 데이터 샘플을 준비하는 과정이며, epsilon값에 의해서 무작위 행동을 하거나, 아니면 정책 신경망의 결정에 의해서 매수나 매도, 혹은 관망을 하게 됩니다.

다음은 행동에 의한 결과를 메모리에 저장하는 부분인데, 129번 줄에서 모든 데이터를 모아서 2차원의 배열로 만드는 것을 볼 수 있습니다. 그리고 만약에 무작위 행동을 했는 경우라면 136번째 줄에서 나와 있는 것처럼 정책 신경망의 결과를 저장하는 부분에서 nan이라고 하는 NumPy 라이브러리의 Not A Number라는 뜻의 nan을 넣는 것 입니다.

그리고 나서 batch의 사이즈, 반복을 했는 횟수, 무작위 투자 횟수, 그리고 win_cnt라고 해서 수익이 발생한 횟수등을 증가 시키는 과정을 거치게 됩니다. 아직 정책 학습기 모듈을 다 만들지 않았지만, 너무 내용이 많아서 이 부분도 2부분으로 잘라서 2개의 포스팅에서 나누어서 올리고자 합니다. 나머지 내용을 남은 포스팅에서 이어서 올릴 것을 약속드리며, 이번 포스팅은 여기서 마치도록 하겠습니다.
'무모한 도전-주식 인공지능 만들기' 카테고리의 다른 글
| 키움증권 HTS(홈 트레이딩 시스템)인 영웅문4의 설치와 데이터 가지고 오기 (2) | 2018.10.29 |
|---|---|
| RLtrader의 제작 part6-final! (4) | 2018.10.22 |
| RLtrader의 제작 part4 (0) | 2018.10.20 |
| RLtrader의 제작 part3 (0) | 2018.10.19 |
| RLtrader의 제작 part2 (0) | 2018.10.18 |