안녕하세요?
일단 너무 한꺼번에 많은 것을 하다보니 무언가가 좀 뒤죽박죽이 되었는데, 아무튼 그럼에도 불구하고 일단은 기계학습은 학습이고, 예측을 하기 위해 적용하는 것은 따로 있습니다. 일단 이 작업을 위해서 가자가지 먼저 예측결과를 분석해 보도록 하고, 그 다음으로는 20만 에포크의 기계학습에 들어갔습니다.
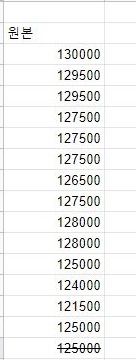
일단 하나 짚고 넘어가야 하는 것이 있는데, 원본 데이터에서 가장 마지막 값은 실제로는 이 값들이 아니라, 다음날의 close값을 예측하는 것이 더 중요합니다.
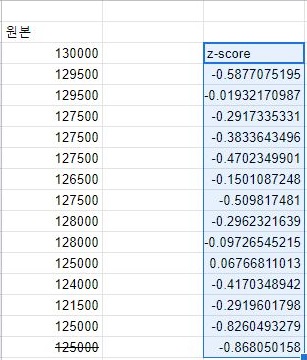
그래서 원본의 제일 첫 머리에 있는 값을 사용이 가능해도, 가장 마지막에 나오는 값은 사용할 수 없는게, 이 값이야 말로 z score의 다음날 오기전의 값이기 때문입니다.

거기다가 원본 데이터의 평균과 표준편차를 이용해서 일단 z score값을 다시 원본값에 가깝게 변환하고, 원본과의 차이를 구했습니다.

일단 차이값을 기존에 - 값을 그래도 두고서 어떻게 평균을 구하는 것이 아니라, 그대로 절대값으로 바꾸고 나서 평균을 구하자, 좀 커진 값이 나옵니다.

문제는 기존의 2000에포크든 2만 에코크든 큰 차이가 없다는 것 입니다. 그래서 변수를 창출하기 위해서 한번 극단적으로 큰 훈련 횟수를 주기로 했습니다.

그래서 아예 위 스크릔샷에서 보이는 것처럼 상당히 많은 양의 기계학습을 시키고자 했습니다. 일단 이거 다 되기는 기다리는 것도 일이였습니다.

결국 상당한 시간이 흐른 끝에 어떻게 멈추게 되었는데 정말로 반나절이 넘게 걸릴만큼 정말 오래 걸린 작업 이기는 이었습니다.

일단 이렇게 해서 하나 모델이랑 그 결과를 만들어 내는데 성공하긴 했습니다. 이제 학습결과를 살펴볼 시간 이기는 합니다.

일단 성공적으로 loss값이 줄어들어서 예측과 원본값이 많이 일치하는 것으로 보이는 상황이 나온 값도 있습니다만, 그렇지 않은 경우도 있습니다.

이렇게 처음부터 nan이 떠서, 제대로 학습이 되는 것이 맞는지 아닌지도 의문이 드는 경우마져 나오고 있습니다. 이걸 어떻게 할지도 장차 고민일 듯 합니다.
아무튼 이렇게 말도 많고 탈도 많은 모델이지만, 이를 이용해서 위 스크린샷과 같은 예측값의 데이터 베이스를 얻는데 성공했습니다. 이제부터는 이를 바탕으로 해서 한번 원본값을 역추적해나갈 수 있으니, 그 과정을 밟아봐야 합니다. 그런데 이번 포스팅은 너무 길어져서 한번 끊어 주도록 해야 합니다.
'무모한 도전-주식 인공지능 만들기' 카테고리의 다른 글
| 다시 2차로 도전하는 기계학습으로 주가 예측하기 -11- (0) | 2022.01.27 |
|---|---|
| 다시 2차로 도전하는 기계학습으로 주가 예측하기 -10- (0) | 2022.01.27 |
| 다시 2차로 도전하는 기계학습으로 주가 예측하기 -8- (0) | 2022.01.27 |
| 다시 2차로 도전하는 기계학습으로 주가 예측하기 -7- (0) | 2022.01.27 |
| 다시 2차로 도전하는 기계학습으로 주가 예측하기 -6- (0) | 2022.01.24 |



