안녕하세요?
막상 아이디어 자체는 머신러닝을 통해서 예측을 한다지만, 이 한마디를 실행하기 위한 작업은 결코 간단한 것이 아니었습니다. 심지어 이 작업 때문에 Yukkuri Run!의 개발도 지연이 되고 있지만, 그래도 많은 지연은 안될 것이, 일단은 얘네를 가지고서 간단한 기계학습까지는 들어가 볼 예정입니다. 우선 여기서 한가지 문제가 그전에 생기기는 생겼습니다.

가장 큰 문제는 뭐니뭐니 해도, 제공하는 데이터가 너무 많다는 것 입니다. 일단 1997년 데이터를 제가 여기에 사용할 필요는 없다는 생각이 듭니다.

그래서 먼저 구글 코랩상에서 자르기를 시도해 보았습니다만, 이게 만만치 않은 것이, 일단은 얘네가 판다스 데이터 프레임이 아니라 다른 형태라서, 기존의 방법으로는 도저히 답이 없습니다.

그래서 파이참에서 데이터를 확보하는 과정에서 부터 먼저 손을 써 두도록 했습니다. 지금은 위 스크린샷을 보시면 알 수 있듯이 일단은 2015년 자료만 가지고서 한번 작업을 해 보는 것 입니다.
어쨎든 이 방법을 써서 위 스크린샷에서 볼 수 있는 것과 같이 일단은 일련의 테스트용 데이터 셋을 확보하는 데 까지는 성공적으로 끝이 나기는 났습니다.

그리고 결과를 보면 어떻게 OBV값을 계산해 냈으며, 이 값이 언제부터 시작하느냐에 따라서 어떻게 값이 달라지기 때문에, 상당히 중요해 보입니다.

그리고 일일히 데이터를 수정해서 하기는 힘들기 때문에 일단 GUI를 만들어서 적용을 시켜 주도록 합니다. 이렇게 하나 만들어서 작업을 해서 제대로 작동을 하는지 봐야 합니다.
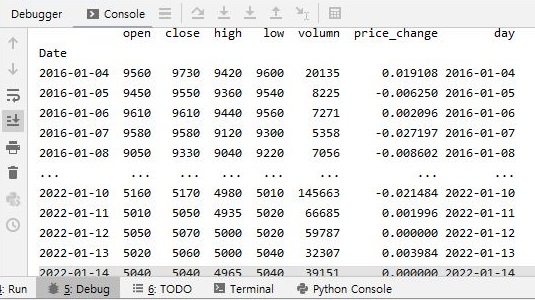
2016년 부터 어떻게 데이터를 얻어서 오라고 했더니, 제대로 가지고 오는 것을 확인할 수 있었습니다. 일단 이 결과로 인해서, 일단은 작업이 제대로 되기는 되는 것으로 보입니다.

먼저 테스트용 데이터를 가지고서 한번 csv파일로 저장이 가능한지 여부를 알아보도록 했습니다. 그리고 나서 다음으로 OBV를 계산하고........

테스트용 데이터 베이스를 확보하는 것 까지는 어떻게 성공했습니다. 이제 남은 것은 진짜로 실험에 사용하기 위해서 어떻게 작업을 해 주어야 합니다.

이전 포스팅에서 언급이 되어 있는 과정을 거쳐서, 어떻게 위 스크린샷에서 볼 수 있는 것처럼 제대로 코스피와 코스닥의 데이터 베이스를 확보했습니다. 이제 얘네를 가지고서 어떻게 기계학습을 진행할 것인지 알아봐야 하는데, 이때 까지만 해도 이게 얼마나 머리아픈 일이 될지는 몰랐습니다.
'무모한 도전-주식 인공지능 만들기' 카테고리의 다른 글
| 드디어 본격적인 pytorch의 적용 -2- (0) | 2022.01.18 |
|---|---|
| 드디어 본격적인 pytorch의 적용 -1- (0) | 2022.01.18 |
| 겨우겨우 성공한 OBV계산결과가 있는 데이터 더미 part2 (0) | 2022.01.16 |
| 겨우겨우 성공한 OBV계산결과가 있는 데이터 더미 part1 (0) | 2022.01.15 |
| 오랫만의 파이썬, 오랫만의 걸림돌 (0) | 2022.01.14 |



