안녕하세요?
이래저래 사정이 있어서 이 통계학 포스팅도 많이 늦어졌는데, 아무튼 어찌저찌해서 이번 포스팅에서는 변동계수, 상관계수, 그리고 순위상관계수에 대해서 한번 포스팅을 하고자 합니다. 먼저 언급해야 하는 것으로 변동계수 (coefficient of variation)을 언급하고자 합니다.

먼저 관측 데이터 A와 B에 대해서 한번 이야기를 하도록 해 보겠습니다. 일단 A와 B는 데이터의 크기가 서로 다르다는 것을 얼핏 보면 보입니다.

그래서 산술평균과 표준편차를 구하면, 위 스크린샷과 같은 결과를 얻을 수 있습니다. 일단 표준편차가 크다고 해서, 단순히 관측 데이터 A가 평균에서 데이터가 더 많이 분산이 되었다고 할 수 있느냐 하면, 그건 아니라고 할 수 있습니다. 왜냐하면 데이터의 전체적인 관측값이 크기 때문에, 혼선이 일어날 수 있기 때문입니다. 그래서 이런 상황과 같이 데이터의 산술평균이 다른 경우, 얼마나 데이터가 평균에서 흩어져 있는지 정도를 알아보기 위해 필요한 지수가 바로 '변동계수'인 겁니다.

변동계수를 계산하는 방법은 간단하게도 표준편차를 산술평균으로 나누기만 하면 됩니다. 이렇게 해서 나온 변동계수를 한번 계산해 보면, 표준편차가 더 크다고 해서 흩어진 정도가 더 많이 흩어진게 아니라, 실은 같은 수준으로 흩어져 있다는 것을 알 수 있습니다.

다음은 상관계수 (coefficient of correlation) 에 대해서 이야기를 하도록 해 보겠습니다. 일단 이 지수는 두 변수간에 관련성(상관)이 얼마나 강한지를 알아보기 위한 지표입니다. 여기서 19세기의 수학자였던 칼 피어슨이 고안해 낸 피어슨의 적률 상관계수라는 공식이 사용이 된다고 합니다.

일단 피어슨의 적률상관계수는 -1에서 1사이의 값을 가지며, 0에 가까울 수록 두 변수간에 아무런 관계가 없음을 말하고 있습니다. 그리고 위 그림에 표시된 R이라는 값이 1에 가까워 질수록 양의 상관관계라고 해서 한쪽이 커지면 다른 한쪽도 커지는 관계가 됩니다. 반대로 -1에 가까울 수록 음의 상관관계라고 해서, 한쪽이 커지면 다른 한쪽은 반대로 작아지는 관계가 되는 것 입니다.
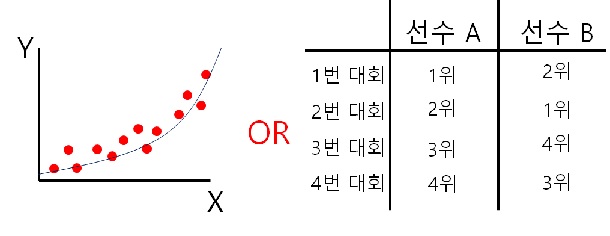
그런데 이런 상관계수를 그냥은 사용할 수 없는 경우가 있습니다. 대표적인게 위 그림의 경우라고 할 수 있는데, 두 변수의 상관관계가 곡선을 그리는 것이 예상이 되거나, 우측의 도표처럼 데이터가 순위 데이터라고 해서 대회에서 거둔 순위만 있는 경우가 해당이 됩니다. 이런 경우는 순위상관계수 (coefficient of rank correlation) 을 사용해야 합니다.

이 순위상관계수를 구하기 위해서는 두가지 방법이 있는데, 우선 첫번째 방법이 '스피어만의 순위상관계수'라고 하는 방법이 있습니다. 이 방법은 기존의 피어슨의 적률상관계수를 구하는 방법과 거의 흡사한 방법으로 계산을 한다고 볼 수 있습니다.

다음은 켄달의 순위상관계수를 구하는 방법입니다. 이 방법은 먼저 위 스크린샷처럼 두 선수의 각각의 대회별로 우열이 일정했는지, 역전이 되었는지를 한번 고려해서 우열이 언제나 일정한 경우를 일치한 횟수, 불일치한 횟수를 계산해야 합니다.

그렇게 해서 위 그림처럼 계산을 하면 되기는 됩니다. 일단 여기서 순위상관계수를 구하기 위해서는 스피어스의 방법이냐 켄달의 방법이냐가 갈리고 있는데, 어느것이 정답인지 모른다고 할 수 있습니다. 딱히 어느것을 써야 한다고 정해진 것은 없다고 할 수 있습니다.

그리고 나서 추가로 언급하고 넘어가야 하는 것이 바로 조합의 수를 구하는 방법입니다. 제일 위에는 n개에서 2개를 고를 경우 나오는 조합의 수를 구하는 공식이며, 그 아래에 있는 것은 n개에서 x개를 조합해서 구할 수 있는 수를 계산하는 공식입니다. 이렇게 부록까지 언급을 해서, 변동계수, 상관계수, 순위상관계수를 구하는 방법에 대해서 통계학 포스팅을 완료 했습니다.
'무모한 도전-주식 인공지능 만들기 > 통계학 공부' 카테고리의 다른 글
| 통계학 도감의 서문 - 통계학을 배우는 이유 (0) | 2026.01.28 |
|---|---|
| 확률분포의 균일분포 (0) | 2020.02.25 |
| 사분위수, 편차와 분산, 그리고 표준편차 (0) | 2019.10.27 |
| 평균의 3가지 종류-산술 평균, 기하 평균, 조화 평균 (0) | 2019.10.22 |



