안녕하세요?
이번 포스팅에서는 어떻게 해서 시간이 없다 보니까, 일단 100%가 되지는 않더라도 어느정도 정보를 얻는데 성공했다면, 이를 바탕으로 해서 한번 작업을 들어가 보고자 합니다.

일단 작업을 위해서 numpy를 가지고 오도록 합니다. 왜 이러나 하면, ndarry라고 numpy에 있는 다차원 array를 그냥 numpy로 돌리는데 성공했지만, 이걸 str형식으로 바꾸어 줄 필요성이 있기 때문입니다.
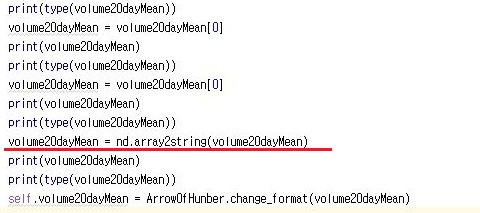
다음으로 할 일은 위 스크린샷처럼 한번 array2string을 가지고 작업을 하도록 합니다. 이 작업에서 드디어 string으로 가는 것을 확인할 수 있습니다.

그리고 제대로 string형식의 변수로 변환이 되었는지 확인해 보기 위해서, 한번 type을 print()함수로 나오게 했더니, 위 스크린샷처럼 제대로 str로 나오는 것을 확인할 수 있었습니다.

그리고 나서 위 스크린샷처럼 제대로 나오는 stockInformation이라는 텍스트 파일이 생성이 되는 것을 확인할 수 있었습니다.

일단 정보가 제대로 찍혀 있는 것 까지는 확인할 수 있었습니다. 이제 남은 작업은 위 텍스트 파일을 엑셀로 열어서 정보가 얼마나 일치하는 지 알아보는 것 입니다.

먼저 엑셀파일에서 앞서 말한 대로 열어서 아무 종목이나 한번 찍어서 확인을 하러 가도록 해 봅니다. 정보는 네이버 금융페이지에서 얻도록 합니다.

그런데 현재가와 거래량이 100% 일치하지 않았습니다. 아마도 프로그램을 처음으로 만들때 나오는 TR이 잘못된 것이라는 생각이 들지만, 문제는 이때가 거의 아침 7시에 가까웠습니다.

그래서 하는 수 없이 일단 이 부정확한 정보를 가지고서 어떻게 29개의 종목-정확히는 1개 잘못 골라서 28개의 종목을 코스닥과 코스피에서 선택할 수 있었습니다.

다음으로는 코스피에서 위 스크린샷과 같이 평균회귀 테스트 결과 그 값이 30미만인 종목만들 추려 보도록 했습니다. 그리고 나서 부정확하긴 하지만 일단 InformationHunter에 돌리도록 했습니다.

이렇게 해서 리스트라는 텍스트 파일에 넣어서 한번 돌려 보도록 했습니다.

다음으로는 코스닥에서 평균회귀 테스트 결과 30미만의 값이 나온 종목들을 가지고서 한번 작업에 들어가 보도록 합니다.

이 리스트들을 모두 텍스트 파일에 집어 넣는 것으로 해서, 코스닥의 정보도 가지고 오도록 합니다. 비록 부정확하긴 해도 쓸 수 있으리라 생각을 했습니다.

이렇게 하는 것으로 코스닥과 코스피를 통틀어서 모두 50개의 종목을 속히 선정하는 데는 성공했습니다. 물론 더 정확한 정보가 필요한 것도 맞지만, 문제는 시간이었습니다. 일단 급하게 들어가 볼 새로운 실험이 있어서, 여기까지는 해봐야 다음이 어떻게 될지 알 수 있기 때문입니다. 다음 포스팅에서는 새로운 실험에서 어떤 결과가 나왔는지에 대해서 올려 보도록 하겠습니다.
'무모한 도전-주식 인공지능 만들기' 카테고리의 다른 글
| 2019년 8월 13일 주식 모의투자에 들어가 본 결과 (0) | 2019.08.14 |
|---|---|
| 2019년 8월 12일 주식 모의투자에 새로 들어가 보기 (0) | 2019.08.13 |
| 2019년 8월 둘째주 평균회귀 테스트-3- (0) | 2019.08.13 |
| 2019년 8월 둘째주 평균회귀 테스트-2- (0) | 2019.08.12 |
| 2019년 8월 둘째주 평균회귀 테스트 (0) | 2019.08.12 |



