안녕하세요?
지난번 포스팅에서 어떻게 데이터를 정리해서 비교 분석하고 일치하는 결과를 추출하기 위해서 이래저래 list를 한번 시도해 보았습니다만, 문제는 상황이 녹녹치 않아서 그만 더 이상은 리스트를 사용한 작업은 무리라는 생각이 듭니다. 그래서 이번에는 pandas의 데이터 프레임을 사용해서 작업을 하고자 합니다.

먼저 리스트로 만들면서 모든 요소 하나하나를 분리하지 말고, 일단 한줄의 요소만 따로 떼어서, ;를 기준으로 분리를 하도록 for문 하나를 제거해 줍니다.

이렇게 해서 결과가 어떻게 나오는 지에 대해서, 한번 print()함수를 이용해서 이렇게 알아보는 작업에 들어가 보도록 합니다.

이렇게 하는 것으로, 모두 리스트에서 요소 하나가 다시 리스트 안의 리스트로 하나씩 묶여 있는 것을 확인할 수 있기는 있었습니다.

그리고 자료를 한번 검색해 보았더니, 위 스크린샷과 같이 리스트를 일종의 pandas의 데이터 프레임 형식으로 어떻게 바꿀 수 있습니다.
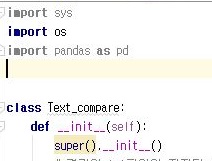
그리고 나서, 위 스크린샷에서 나오는 것 처럼, 먼저 py파일에 pandas를 한번 위 스크린샷에서 보이는 것처럼 import를 해 주도록 합니다.

그래서, 위 스크린샷과 같이, 아예 데이터 프레임으로 만들기 위해서 먼저 column의 이름이 될 리스트를 하나 만들어 준 다음, from_records(리스트1번, columns=column명이 적혀있는 리스트2번) 이라는 형식으로 어떻게 만들어 줍니다.

그리고 위 스크린샷과 같이 제대로 된 데이터 프레임 형식으로 나오는 것을 확인할 수 있기는 있었습니다. 그래서 다음으로는 이런 것을 각각의 테스트 별로 만들어 줘야 하는 필요가 있습니다.

그래서 먼저 위 스크린샷과 같이, ADF 테스트면 ADF 테스트, 그리고 허스트 지수면 허스트 지수, 반감기-Half Life테스트도 테스트 대로 데이터 프레임으로 만들어 주도록 합니다.

그리고 나서 이제는 데이터 프레임 2개를 서로 비교분석해서 일치하는 데이터만 추려내는 함수를 사용할 차례입니다. 그 방법은 위 스크린샷에서 나와 있는 것처럼 merge(1번 데이터 프레임, 1번 데이터 프레임, on=['기준이 되는 column명'], how='inner') 이라는 방법을 씁니다. 다음으로는 inner라고 하면 일치하는 데이터만 합쳐주고, outer라고 하면, 일치하는 데이터가 없어도 모두 한개의 데이터 프레임에 통합이 됩니다.

이렇게 하는 것으로 일단 데이터의 통폐합이 제대로 되는 것을 확인할 수 있기는 있었씁니다. 다만 문제는 이게 first클래스라고 해서, 처음에는 너무 중복된 데이터가 많아서 데이터 프레임이 쓸데없이 컸는데, 이 문제는 drop_duplicates()라는 함수를 뒤에 붙여 주는 것으로 해결할 수 있었습니다.

그렇게 데이터 프레임을 얻는다고 해서, 모두 끝이 아니라 이걸 저장해야 할 필요성이 있습니다. 일단 저는 엑셀파일로 저장하려고 하니까, 아나콘다 프롬프트를 열어서 위 스크린샷처럼 pip install openpyxl을 만들어 주도록 합니다.

그리고 나서 관련된 모듈을 py파일에서 import해서 가지고 오도록 합니다. 이제 본격적으로 엑셀파일을 생성할 준비는 끝난 상황입니다.

그리고 나서 데이터 프레임을 to_excel()이라는 함수를 사용해서 엑벨 파일을 열어서 데이터를 저장해 주도록 합니다. 이제 제대로 생성이 되었느냐 하면.....

먼저 위 스크린샷에서 보이는 것처럼 위 데이터를 정리해서 나오는 것을 확인할 수 있었습니다. 먼저 위 스크린샷에서 보이는 것처럼 데이터는 일단 퍼스트 클래스라고 해서, 가장 깐깐한 ADF 테스트를 통과하고 허스트 지수를 가지고 있으면서 평균회귀에 걸리는 시간이 가장 짧은 주가들만 모은 것 입니다. 다만 이것으로 끝이 아니라, 다음으로는 그 다음으로 좋은 결과도 가지고 와야 하는 과제가 남아 있습니다.
'무모한 도전-주식 인공지능 만들기' 카테고리의 다른 글
| 평균회귀 모델의 구현 (0) | 2019.04.30 |
|---|---|
| 결과를 정리하기 위한 txt파일의 비교분석 & 정렬-complete- (0) | 2019.04.30 |
| 결과를 정리하기 위한 txt파일의 비교 분석 & 정렬 (0) | 2019.04.29 |
| 종목선정을 위한 ADF 테스트, 허스트 지수, Half-life테스트 하기 (0) | 2019.04.28 |
| 새로운 방법으로 강화학습을 시도해 보기-5- (0) | 2019.04.27 |



