안녕하세요?
지난번 포스팅에서 언급한 대로, 강화학습으로 만들어진 모델이 2종류의 패턴을 만들어 내는 것을 보이자, 강화학습에 사용된 횟수가 부족한 것이 아닌가 해서 300에포크로 늘려서 강화학습을 한번 시켜보고, 그 결과를 포스팅 해 보고자 합니다.

먼저 위 스크린샷에 보이는 것처럼, 100으로 되어 있던 수치를 300으로 올려 보도록 해 보아야 합니다. 물론 위 화면은 yellowoperation에 있는 main.py를 수정한 것 입니다.

첫번째 강화학습의 경우 1시간 50분이 걸려서 끝난 것을 확인할 수 있었습니다. 일단 첫번째 모델의 강화학습이 끝났으니, 구글 코랩에서는 두번째 강화학습을 돌리도록 합니다.

다운로드한 첫번째 강화학습의 모델을 가지고 오도록 합니다. 그리고 나서 RLTrader를 작동시킨 다음에 백테스트에 사용할 데이터의 비율을 50%로 지정하고 들어가도록 합니다.

그래서 위 스크린샷에서 보이는 것처럼 어째서인지 모르겠지만, 지난번 100에포크로 돌렸을 때와 비교해서 전혀 큰 차이가 없는 결과가 나온 것을 확인할 수 있었습니다.

그러는 와중에 두번째 강화학습이 1시간 50분 가까이 걸리면서 끝이 나는 것을 볼 수 있었습니다.

구글 드라이브에서 다운로드 해서, 다음으로 50%의 데이터를 지정해서 RLTrader에서 백테스트에 들어가 보도록 합니다.

그리고 나서 위 스크린샷에 나오는 것처럼 첫번째와 같은 결과가 나오는 것을 볼 수 있었습니다.

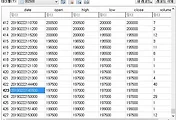
문제는 위 스크린샷에서 보이는 것처럼 강화학습을 하든, 백테스트를 하든, 첫번째 결정을 내리기 이전의 120행의 데이터를 필요로 하는데, 이 과정에서 먼저 매수를 무조건 하는 경향이 있다는 것을 알 수 있습니다. 그래서 위 스크린샷에서 보이는 것처럼 매수를 무조건 하는 것을 어떻게 해서든 막아야 하는데, 문제는 프로그램의 코드에서 이걸 어떻게 하느냐 입니다.
'무모한 도전-주식 인공지능 만들기' 카테고리의 다른 글
| 인공지능의 묻지마 매수를 막기위한 작업-2- (0) | 2019.03.01 |
|---|---|
| 인공지능의 묻지마 매수를 막기위한 작업-1- (0) | 2019.03.01 |
| 좀 더 많은 백테스트 data를 가지고 했는 결과 (0) | 2019.02.27 |
| 종목코드 002600으로 첫번째 시도를 했는 결과 (0) | 2019.02.25 |
| 100에포크 강화학습과 부딪친 한계 (0) | 2019.02.24 |